
Introduction
So, this is the first post on a series of automation posts that will demonstrate how to build a Full-Stack automation. In fact it can be used to automate any service, but we'll focus and use network as an example.
This first post will cover the idea of the solution, its architecture, components and other useful information. I'll try my best to not use marketing or specific definitions like SD-WAN, SDN, SaaS, IaaS, etc.
First of all, let's be clear about what is considered "full-stack automation" regarding this series of posts. Full-stack automation is referred as a solution/architecture to fully automate network (or any other services), beginning on the automation itself (eg.: playbooks that will run commands on a Automated Resource) all the way up to a structured data source using gitlab, an API and a WEB interface to be used by final users of the solution.
After building all this architecture, users should be able to access a page, input some information/value in it (eg.: routes, acls, interfaces IP address, etc.) and watch it being deployed by ansible on a Automated Resource (eg.: router)
If you are on a hurry and don't want to read further, the installation scripts and demo can be found in this repository: https://github.com/liviozanol/full-stack_automation.
The Architecture
The architecture presented in this series of posts, which is shown below, is intended to be agnostic of manufacturer and cover any service automation, in a structured, secure and scalable way. Each piece was thought of in a way that can be exchanged by another solution with little/no adjustment on other pieces. You could change gitlab for files, change hashicorp vault for ansible secrets, change the API programming language to any other that you want, change the web user interface for other you want.

This series of posts will detail every layer/element of the architecture, also providing a guide on how to install and configure each one of them. In the end you should have a complete functional Full-Stack Automation solution based on this architecture and also a demo.
Description of each element/layer:
The web interface will provide a friendly interface to users where they can list, create, update or delete data from a browser.
The API will provide a single point of contact for all automation and is responsible to receive user requests on data modifications (eg.: change network interface ip address), validate the data and send it to gitlab.
Gitlab is used as a place to store structured data from users (like a database), and also ansible playbooks.
Gitlab-CI/Runner will listen for data modifications on gitlab and call AWX to execute playbooks.
AWX/ansible will execute playbooks to implement the data modified by users in Automated Resources.
Hashicorp Vault will store key/pass to access Automated Resources and also key/pass to interact between elements (git lab token, etc.).
Automated Resource is a piece of infrastructure that provides some IT service. It can be a router/switch, a firewall, a hypervisor (eg.: vmware vsphere, openstack), a virtual machine, a container, etc. A router will be used as an example. Since we are using ansible, almost anything can be automated. You can even manage a terraform deployment to extend it even further (https://docs.ansible.com/ansible/latest/collections/community/general/terraform_module.html)! The resource is only accessed by ansible and using credentials stored in a specific Hashicorp Vault. You can also use other middle/tunnel/bastion infrastructure to access the Automated Resource through ansible, like a SSH tunnel.
Why/When to use Full-Stack Automation?
When you have services/functions that needs to be used by final users to manage a provided infrastructure by you. Examples:
You are a cloud provider and your users needs a portal/API/console/terraform module to manage the infrastructure you provide (just like current cloud providers: AWS, Azure, Google Cloud, Digital Ocean, etc.);
You are a service provider and you want(or need) that your users be able to change some configurations remotely for the provided infrastructured using a portal/API. (eg.: create ACLs on a remote CPE router you provide for them)
You have an operation team and you want to provide a portal/API to operators to provise or change infrastructure. (eg.: install and manage CPEs on a WAN network)
You just want to test the architecture or learn more about automation.
Why/When NOT use Full-Stack Automation?
When you don't need/want to provide infrastructure services in a self-service manner to the end user or When you have a small team that can manage the infrastructure directly.
Either way, the architecture designed can also be used for any cases on any element. You can, for example, just provide access to gitlab files and let your technical team modify direct information (a.k.a gitops) and leverage on the CI/CD + AWX solutions to implement it on your infrastructure. You can also provide direct access to AWX so operators just complete a web form (like a normal AWX use).
Automation Scenario Used
We will use a scenario as an example to implement a demo for the Full-Stack Automation architecture described here.
Assertions:
You work on a network service provider that serves WAN connections to several clients.
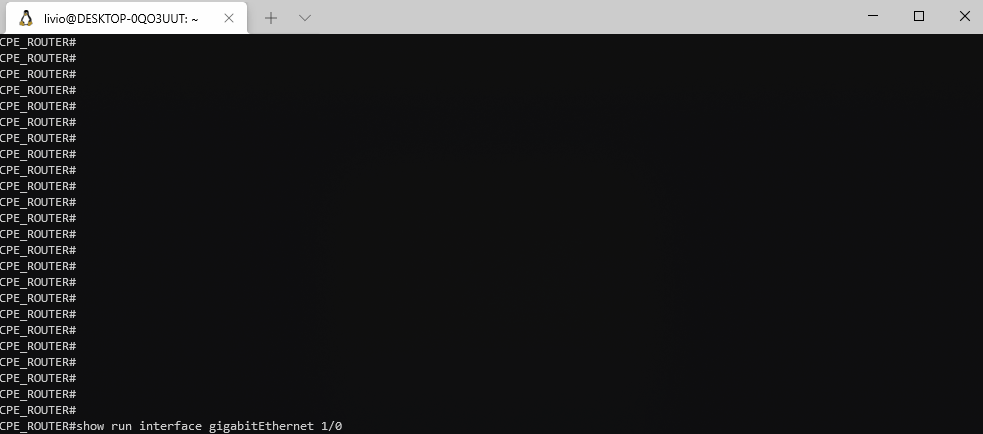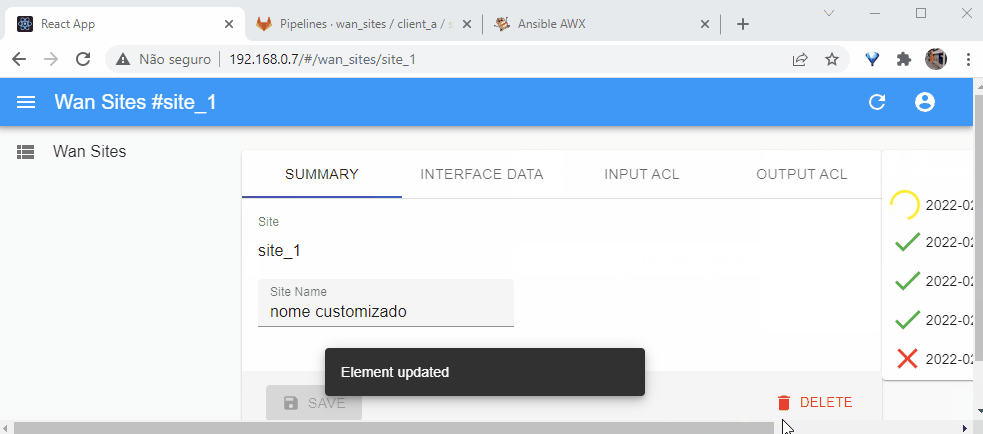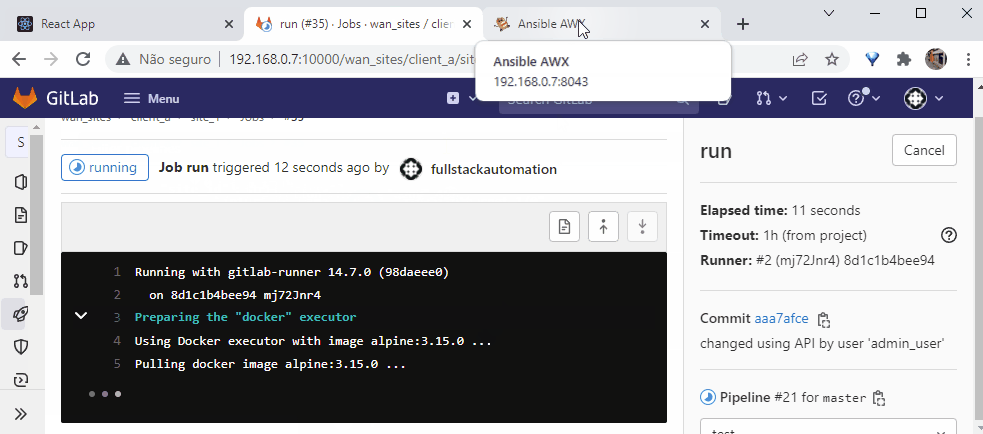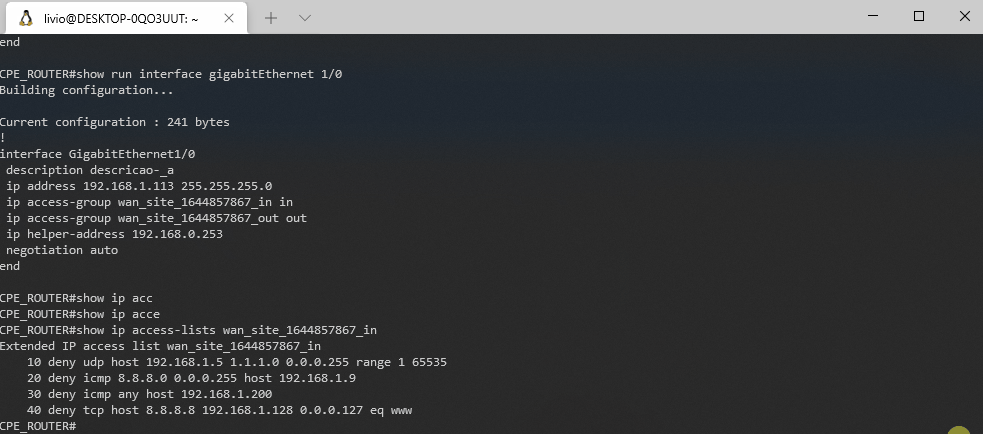
The network topology has CPEs (routers installed on clients premises) for every remote site that is connected to the provider network and that router connects each client site LAN to your transport network. You are required to allow clients to modify some configurations on these CPEs.
Clients should be able to change configuration for all CPEs installed on their remote sites.
Clients must only modify configuration for the LAN interface of CPEs.
Clients should be able to modify configuration for interface description, interface IP address/subnet, interface ACLs and helper address/dhcp relay (DHCP server address).
Clients should be able to access a web page to make modifications. They should be able to also do these actions through an API.
System Requirements
The simulated architecture will run on a single machine. In a production environment you may need to adjust it by separating elements in different secure segments and adding one or more pieces of softwares as needed.
Since it's on a single machine you'll need some good amount of FREE RAM memory (around 8GB), around 20GB of free disk space and a decent CPU. Since this is a demo, you have the option to use gitlab.com (or other gitlab) instead of intalling one and save about 3-4GB of RAM, be needs to adjust the steps/scripts.
It'll be used docker-compose and some custom scripts to build the solution. You could install it using pure docker or kubernetes, adjusting scripts and files, of course.
You can run the scripts on a VM using a virtual box, another hypervisor (vmware, 'aws', openstack, etc) or use WSL on windows (which is also a VM by the way). Running the demo on a VM is a nice option.